How to visualise internal linking in Python using NetworkX graphs
Learn how to scrape a website's internal linking in Python and visualise the connections between pages using NetworkX network graph visualisations.

Adding internal links to articles helps reduce bounce rate by promoting related content site visitors may find interesting, but it also has a powerful impact upon search engine optimisation or SEO. Effectively, internal links tell Google what content is related and that you consider it important.
Therefore, most site owners take time to check that they’ve added internal links to the right pages to connect related content together into content hubs or topic clusters. While you can examine the internal linking used on your site simply by scanning the raw data, with some Python SEO skills, you can also visualise your site’s internal linking structure using a network or graph visualisation.
Graph visualisations have been around for decades and are used as a way of representing connections between datapoints - or nodes and edges as they’re called in graph theory terminology. Graph or network data visualisations are often used for representing social network data, but are also perfect for visualising how content on a website is interconnected via internal linking.
In this project we’re going to scrape the XML sitemap from a website, write some code to crawl selected pages and extract and identify the internal links, store the output in a Pandas dataframe, and create a network graph visualisation showing how the articles are connected together via internal linking. There’s quite a bit of code, but we’ll break everything up into simple steps to follow.
Import the packages
To get started, open a Jupyter notebook and import the Python packages below. Some of these packages are pre-installed on the Docker NVIDIA Data Science Stack I use for data science work, but others, such as RequestsHTML, EcommerceTools, and networkx need to be install using the Pip Python package management system.
Since we’re going to be displaying long URLs in Pandas dataframes, we’ll also use the Pandas set_option() function to configure Pandas to show wider columns and more rows to make it easier to view the data we scrape.
!pip3 install requests_html
!pip3 install ecommercetools
!pip3 install networkx
import requests
import urllib
from urllib.parse import urlparse
import pandas as pd
from requests_html import HTML
from requests_html import HTMLSession
from ecommercetools import seo
import networkx as nx
import matplotlib.pyplot as plt
%matplotlib inline
pd.set_option('max_rows', 1000)
pd.set_option('max_colwidth', 1000)
Download an XML sitemap and import into Pandas
First, we’ll use the seo module from EcommerceTools (a Python data science toolkit for ecommerce, marketing, and SEO) to fetch the XML sitemap for a website and return the URL or loc in a Pandas dataframe. Since we only want HTML pages containing links, we need to remove any other pages, such as PDFs, that might appear in the sitemap but can’t be scraped.
df = seo.get_sitemap("https://www.practicaldatascience.co.uk/sitemap.xml")
df = df[['loc']]
df = df.loc[~df['loc'].str.contains(".pdf", case=False)]
df.head()
| loc | |
|---|---|
| 0 | https://practicaldatascience.co.uk/data-science/how-to-create-a-python-virtual-environment-for-jupyter |
| 1 | https://practicaldatascience.co.uk/data-science/how-to-engineer-date-features-using-pandas |
| 2 | https://practicaldatascience.co.uk/machine-learning/how-to-impute-missing-numeric-values-in-your-dataset |
| 3 | https://practicaldatascience.co.uk/machine-learning/how-to-interpret-the-confusion-matrix |
| 4 | https://practicaldatascience.co.uk/machine-learning/how-to-use-mean-encoding-in-your-machine-learning-models |
Scrape the internal links from the pages
Next, we need to scrape the pages from the sitemap and extract the required information from the pages. Many excellent SEO tools, such as Screaming Frog, allow you to do this, but we’ll do it from scratch in Python.
To make the code a bit clearer, and allow you to re-use the elements, we’ll create a separate function for each step in the process and use the Python try except process to catch any errors or exceptions. First, we’ll use RequestsHTML to fetch the HTML source of each page. Once we’ve got this, we can then parse out the chunks we need.
def get_source(url):
"""Return the source code for the provided URL.
Args:
url (string): URL of the page to scrape.
Returns:
response (object): HTTP response object from requests_html.
"""
try:
session = HTMLSession()
response = session.get(url)
return response
except requests.exceptions.RequestException as e:
print(e)
To extract the page title we’ll use find() to return the text contained in first title element we find in the html object returned in response.
def get_title(response):
return response.html.find('title', first=True).text
Rather than returning all the links found in the page, which will include so-called “boilerplate” content, such as the header and footer, and sidebar links, we’re only interested in the links that are present in the main body of each article. We can use find() to extract these a HTML elements containing the link by specifying the HTML class .article-post in which the site wraps each post’s body.
def get_post_links(response):
return response.html.find('.article-post a')
Later, it’s going to be beneficial for us to be able to tell the difference between internal links and external links, so we can use URL parsing to determine the type of each link. If the URL is relative (i.e. it contains no HTTP protocol prefix) then it must be internal, so will any links that start with the same domain as the site, while any other URLs must be external.
def is_internal(url, domain):
if not bool(urlparse(url).netloc):
return True
elif url.startswith(domain):
return True
else:
return False
Finally, we’ll wrap up those functions and loop through the list of URLs to extract the title, links, and link type found on each page. This isn’t the fastest way to scrape a website, so I’d recommend only using it on smaller sites, otherwise it will take forever. For larger sites you’d benefit from creating asynchronous connections, or just using a more powerful scraping tool, such as Screaming Frog or Advertools.
def scrape_links(df, url_column, domain):
df_pages = pd.DataFrame(columns = ['url', 'title', 'post_link_href', 'post_link_text', 'internal'])
for index, row in df.iterrows():
response = get_source(row[url_column])
data = {}
data['url'] = row[url_column]
data['title'] = get_title(response)
post_links = get_post_links(response)
if post_links:
for link in post_links:
data['post_link_href'] = link.attrs['href']
data['post_link_text'] = link.text
data['internal'] = is_internal(link.attrs['href'], domain)
df_pages = df_pages.append(data, ignore_index=True)
else:
df_pages = df_pages.append(data, ignore_index=True)
return df_pages
Now you can define the dataframe of URLs to scrape (stored in df), tell the code that it will find the URL in a column called loc, and give it the domain of the site so it can distinguish internal links from external links. After a short while, you’ll get back a Pandas dataframe containing your data. We’ll export the Pandas dataframe to a CSV using to_csv() for later use.
df_pages = scrape_links(df, 'loc', 'https://practicaldatascience.co.uk')
df_pages.head(10)
| url | title | post_link_href | post_link_text | internal | |
|---|---|---|---|---|---|
| 0 | https://practicaldatascience.co.uk/data-science/how-to-create-a-python-virtual-environment-for-jupyter | How to create a Python virtual environment for Jupyter | /data-science/how-to-build-a-data-science-workstation | Ubuntu data science workstation | True |
| 1 | https://practicaldatascience.co.uk/data-science/how-to-engineer-date-features-using-pandas | How to engineer date features using Pandas | NaN | NaN | NaN |
| 2 | https://practicaldatascience.co.uk/machine-learning/how-to-impute-missing-numeric-values-in-your-dataset | How to impute missing numeric values in your dataset | NaN | NaN | NaN |
| 3 | https://practicaldatascience.co.uk/machine-learning/how-to-interpret-the-confusion-matrix | How to interpret the confusion matrix | NaN | NaN | NaN |
| 4 | https://practicaldatascience.co.uk/machine-learning/how-to-use-mean-encoding-in-your-machine-learning-models | How to use mean encoding in your machine learning models | NaN | NaN | NaN |
| 5 | https://practicaldatascience.co.uk/data-science/how-to-use-python-regular-expressions-to-extract-information | How to use Python regular expressions to extract information | NaN | NaN | NaN |
| 6 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://scikit-learn.org/stable/datasets/toy_dataset.html#boston-house-prices-dataset | Boston house prices dataset | False |
| 7 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://practicaldatascience.co.uk/machine-learning/how-to-create-a-linear-regression-model-using-scikit-learn | linear regression | True |
| 8 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://scikit-learn.org/stable/datasets/toy_dataset.html#iris-plants-dataset | Iris dataset | False |
| 9 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset | diabetes dataset | False |
df_pages.to_csv('pages.csv', index=False)
Separate the internal links
Since the function we create earlier adds a boolean True or False value to the internal column depending on whether each link is internal or not, we can now separate out the internal links into a single dataframe, and create another with the external links. Technically, we don’t need the external ones, but you may want to take a look.
df_internal = df_pages[df_pages['internal']==True]
df_internal
| url | title | post_link_href | post_link_text | internal | |
|---|---|---|---|---|---|
| 0 | https://practicaldatascience.co.uk/data-science/how-to-create-a-python-virtual-environment-for-jupyter | How to create a Python virtual environment for Jupyter | /data-science/how-to-build-a-data-science-workstation | Ubuntu data science workstation | True |
| 7 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://practicaldatascience.co.uk/machine-learning/how-to-create-a-linear-regression-model-using-scikit-learn | linear regression | True |
| 14 | https://practicaldatascience.co.uk/machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | https://practicaldatascience.co.uk/data-science/how-to-build-a-data-science-workstation | data science workstation | True |
| 16 | https://practicaldatascience.co.uk/machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | https://practicaldatascience.co.uk/machine-learning/how-to-create-a-classification-model-using-xgboost | XGBClassifier | True |
| 17 | https://practicaldatascience.co.uk/machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | scikit-learn’s built-in datasets | True |
| ... | ... | ... | ... | ... | ... |
| 1337 | https://practicaldatascience.co.uk/sitemap | Sitemap | /data-engineering/how-to-use-apache-superset-to-create-an-ecommerce-bi-platform | How to create a BI platform using Apache Superset | True |
| 1338 | https://practicaldatascience.co.uk/sitemap | Sitemap | /data-engineering/how-to-use-apache-druid-for-real-time-analytics-data-storage | How to use Apache Druid for real-time analytics data storage | True |
| 1339 | https://practicaldatascience.co.uk/sitemap | Sitemap | /data-engineering/how-to-set-up-a-docker-container-for-your-mysql-server | How to set up a Docker container for your MySQL server | True |
| 1340 | https://practicaldatascience.co.uk/sitemap | Sitemap | /data-engineering/how-to-create-ecommerce-data-pipelines-in-apache-airflow | How to create ecommerce data pipelines in Apache Airflow | True |
| 1341 | https://practicaldatascience.co.uk/sitemap | Sitemap | /data-engineering/how-to-use-docker-for-your-data-science-projects | How to use Docker for your data science projects | True |
1121 rows × 5 columns
df_external = df_pages[df_pages['internal']==False]
df_external.head()
| url | title | post_link_href | post_link_text | internal | |
|---|---|---|---|---|---|
| 6 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://scikit-learn.org/stable/datasets/toy_dataset.html#boston-house-prices-dataset | Boston house prices dataset | False |
| 8 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://scikit-learn.org/stable/datasets/toy_dataset.html#iris-plants-dataset | Iris dataset | False |
| 9 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset | diabetes dataset | False |
| 10 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://scikit-learn.org/stable/datasets/toy_dataset.html | optical recognition of handwritten digits dataset | False |
| 11 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://scikit-learn.org/stable/datasets/toy_dataset.html | Linnerud dataset | False |
Similarly, you can use the data we’ve just scraped to identify the pages that contain no internal links whatsoever (you may wish to add some), and the pages that contain neither internal, or external links. Again, you don’t actually need to do this for the internal linking visualisation bit, but seeing as you have the data, you may as well use it for some other things while we’re at it.
df_no_internal_links = df_pages[df_pages['internal']!=True]
df_no_internal_links.head()
| url | title | post_link_href | post_link_text | internal | |
|---|---|---|---|---|---|
| 1 | https://practicaldatascience.co.uk/data-science/how-to-engineer-date-features-using-pandas | How to engineer date features using Pandas | NaN | NaN | NaN |
| 2 | https://practicaldatascience.co.uk/machine-learning/how-to-impute-missing-numeric-values-in-your-dataset | How to impute missing numeric values in your dataset | NaN | NaN | NaN |
| 3 | https://practicaldatascience.co.uk/machine-learning/how-to-interpret-the-confusion-matrix | How to interpret the confusion matrix | NaN | NaN | NaN |
| 4 | https://practicaldatascience.co.uk/machine-learning/how-to-use-mean-encoding-in-your-machine-learning-models | How to use mean encoding in your machine learning models | NaN | NaN | NaN |
| 5 | https://practicaldatascience.co.uk/data-science/how-to-use-python-regular-expressions-to-extract-information | How to use Python regular expressions to extract information | NaN | NaN | NaN |
df_no_links = df_pages[df_pages['internal'].isnull()]
df_no_links.head()
| url | title | post_link_href | post_link_text | internal | |
|---|---|---|---|---|---|
| 1 | https://practicaldatascience.co.uk/data-science/how-to-engineer-date-features-using-pandas | How to engineer date features using Pandas | NaN | NaN | NaN |
| 2 | https://practicaldatascience.co.uk/machine-learning/how-to-impute-missing-numeric-values-in-your-dataset | How to impute missing numeric values in your dataset | NaN | NaN | NaN |
| 3 | https://practicaldatascience.co.uk/machine-learning/how-to-interpret-the-confusion-matrix | How to interpret the confusion matrix | NaN | NaN | NaN |
| 4 | https://practicaldatascience.co.uk/machine-learning/how-to-use-mean-encoding-in-your-machine-learning-models | How to use mean encoding in your machine learning models | NaN | NaN | NaN |
| 5 | https://practicaldatascience.co.uk/data-science/how-to-use-python-regular-expressions-to-extract-information | How to use Python regular expressions to extract information | NaN | NaN | NaN |
Prepare the internal link data for visualisation
Next, we’ll create a Pandas dataframe of internal links by filtering the internal column on the True boolean. As you can see, I’ve been a little inconsistent and have used a mixture of absolute and relative URLs, so we need to tidy these up a bit first.
df_internal = df_pages[df_pages['internal']==True]
df_internal.head()
| url | title | post_link_href | post_link_text | internal | |
|---|---|---|---|---|---|
| 0 | https://practicaldatascience.co.uk/data-science/how-to-create-a-python-virtual-environment-for-jupyter | How to create a Python virtual environment for Jupyter | /data-science/how-to-build-a-data-science-workstation | Ubuntu data science workstation | True |
| 7 | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | https://practicaldatascience.co.uk/machine-learning/how-to-create-a-linear-regression-model-using-scikit-learn | linear regression | True |
| 14 | https://practicaldatascience.co.uk/machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | https://practicaldatascience.co.uk/data-science/how-to-build-a-data-science-workstation | data science workstation | True |
| 16 | https://practicaldatascience.co.uk/machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | https://practicaldatascience.co.uk/machine-learning/how-to-create-a-classification-model-using-xgboost | XGBClassifier | True |
| 17 | https://practicaldatascience.co.uk/machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | https://practicaldatascience.co.uk/data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | scikit-learn’s built-in datasets | True |
We’ll use some Python regular expressions to replace the domain when it appears in the URL, effectively turning any absolute URLs into relative ones, so everything is consistent.
df_internal['post_link_href'] = df_internal['post_link_href'].replace('https://practicaldatascience.co.uk', '', regex=True)
df_internal['url'] = df_internal['url'].replace('https://practicaldatascience.co.uk', '', regex=True)
df_internal.head()
| url | title | post_link_href | post_link_text | internal | |
|---|---|---|---|---|---|
| 0 | /data-science/how-to-create-a-python-virtual-environment-for-jupyter | How to create a Python virtual environment for Jupyter | /data-science/how-to-build-a-data-science-workstation | Ubuntu data science workstation | True |
| 7 | /data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | How to use scikit-learn datasets in data science projects | /machine-learning/how-to-create-a-linear-regression-model-using-scikit-learn | linear regression | True |
| 14 | /machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | /data-science/how-to-build-a-data-science-workstation | data science workstation | True |
| 16 | /machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | /machine-learning/how-to-create-a-classification-model-using-xgboost | XGBClassifier | True |
| 17 | /machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | How to use your GPU to accelerate XGBoost models | /data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | scikit-learn’s built-in datasets | True |
Finally, we’ll rename the Pandas columns to make them a bit more meaningful. We’ll call the page upon which the links appear from and we’ll call each internal link present to, because it represents a link to another page on the site.
df_graph = df_internal[['url','post_link_href']]
df_graph = df_graph.rename(columns={'url':'from','post_link_href':'to'}).fillna('')
df_graph.head()
| from | to | |
|---|---|---|
| 0 | /data-science/how-to-create-a-python-virtual-environment-for-jupyter | /data-science/how-to-build-a-data-science-workstation |
| 7 | /data-science/how-to-use-scikit-learn-datasets-in-data-science-projects | /machine-learning/how-to-create-a-linear-regression-model-using-scikit-learn |
| 14 | /machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | /data-science/how-to-build-a-data-science-workstation |
| 16 | /machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | /machine-learning/how-to-create-a-classification-model-using-xgboost |
| 17 | /machine-learning/how-to-use-your-gpu-to-accelerate-xgboost-models | /data-science/how-to-use-scikit-learn-datasets-in-data-science-projects |
Remove non-articles to show only contextual links
Since our sitemap also contains some pages that aren’t articles, such as tag pages and the sitemap, we’ll exclude these from the dataset before we pass it into NetworkX to visualise the internal linking structure.
df_graph = df_graph[~df_graph['from'].str.contains('/sitemap')]
df_graph = df_graph[~df_graph['from'].str.contains('/tag')]
df_graph = df_graph[~df_graph['to'].str.contains('/sitemap')]
df_graph = df_graph[~df_graph['to'].str.contains('/tag')]
Create a static network graph
Finally, we can get onto the actual network graph visualisation. We’ll use the NetworkX from from_pandas_edgelist() function to do this. We’ll pass in the df_graph dataframe that contains the from page and the to URL and NetworkX will show how the pages are internally linked using a network graph visualisation.
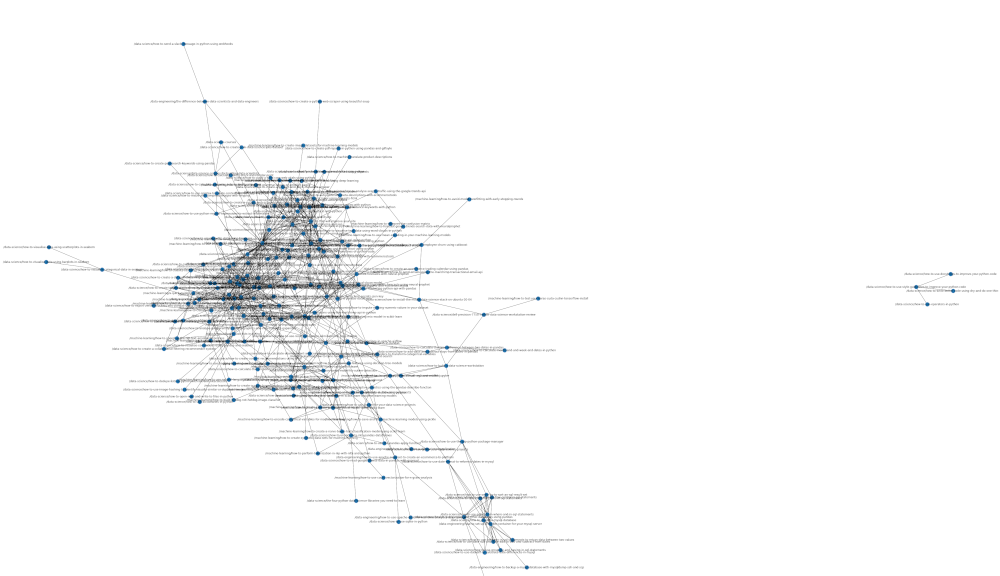
First, we’ll create a simple static network graph visualisation and will use Matplotlib to save out the visualisation to a big image. The downside of this, as you can see, is that it’s very difficult to see the exact details of what’s going on. Saving the visualisation to such a massive image means you can zoom in and have a poke around. It’s not ideal, but you can clearly see that the site has a few topic clusters, where related articles link to each other.
Most of them link to other articles, but there are also a couple of themes where the articles sit on their own, as the topics are a bit different to what I usually cover, or I’ve just failed to add the right internal links to associate them with other topic clusters on the site.
plt.figure(3,figsize=(60,60))
GA = nx.from_pandas_edgelist(df_graph,
source="from",
target="to")
graph = nx.draw(GA, with_labels=True)
plt.savefig('graph.png')
Create an interactive NetworkX graph with Bokeh
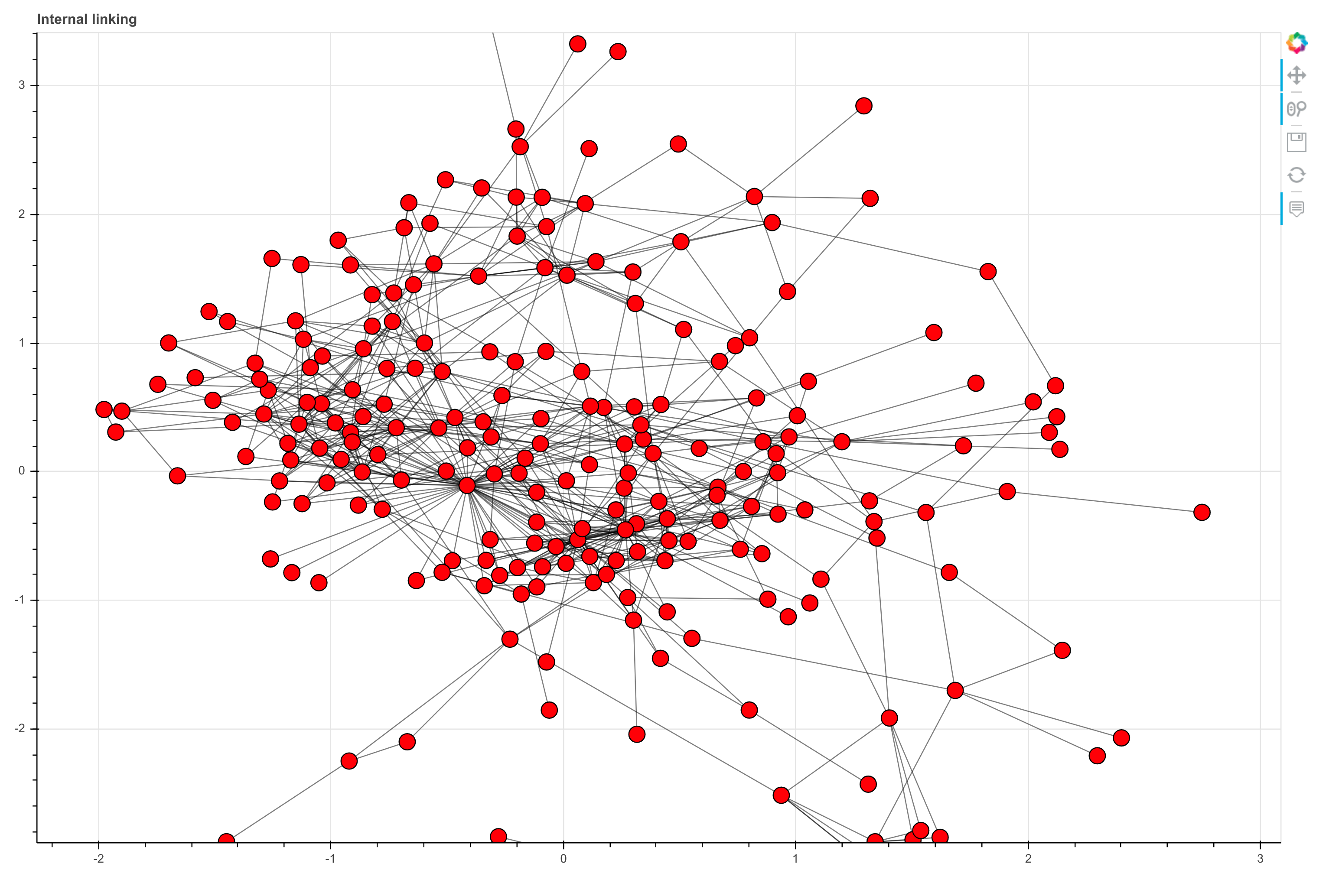
Rather than creating a static image of the network graph visualisation we can use the Bokeh package to create an interactive data visualisation. This will allow us to hover over edges and nodes to reveal information on the linking, and zoom in and out to see more detail than we can with a static visualisation.
To get Bokeh set up in your Jupyter notebook install it with !pip3 install bokeh, import the packages below, and load Bokeh with output_notebook().
from bokeh.io import output_notebook, show, save
from bokeh.models import Range1d, Circle, ColumnDataSource, MultiLine
from bokeh.plotting import figure
from bokeh.plotting import from_networkx
output_notebook()
We can then adapt the code we wrote earlier and pass in the same df_graph dataframe, but use Bokeh to create an interactive network graph. You can hover over each dot to reveal the URL and zoom in and out to investigate a given content cluster to see how it’s interlinked.
GA = nx.from_pandas_edgelist(df_graph,
source="from",
target="to")
plot = figure(tooltips=[("URL", "@index")],
title='Internal linking',
tools="pan,wheel_zoom,save,reset",
active_scroll='wheel_zoom',
x_range=Range1d(-10.1, 10.1),
y_range=Range1d(-10.1, 10.1),
width=1200,
height=800
)
network_graph = from_networkx(GA, nx.spring_layout, scale=10, center=(0, 0))
network_graph.node_renderer.glyph = Circle(size=15, fill_color='red')
network_graph.edge_renderer.glyph = MultiLine(line_alpha=0.5, line_width=1)
plot.renderers.append(network_graph)
show(plot)
Matt Clarke, Tuesday, May 10, 2022













Other posts you might like

How to use the Pandas truncate() function
Have you ever needed to chop the top or bottom off a Pandas dataframe, or extract a specific section from the middle? If so, there’s a Pandas function called truncate()...

How to use Spacy for noun phrase extraction
Noun phrase extraction is a Natural Language Processing technique that can be used to identify and extract noun phrases from text. Noun phrases are phrases that function grammatically as nouns...
