A quick guide to Product Attribute Extraction models
Learn why ecommerce retailers and marketplaces are creating Product Attribute Extraction (PAE) models to identify attributes in product information.

Product attributes, such as size, weight, wattage, or colour, are critical in ecommerce as they help customers find and select the right product for their needs. However, obtaining, adding, and maintaining these values is extremely labour intensive, especially on larger sites.
As a result, a number of ecommerce retailers and marketplaces have developed sophisticated machine learning models that use a Natural Language Processing (NLP) technique called Product Attribute Extraction (PAE) to extricate these values from text.
By utilising PAE models, internet retailers can automatically extract attributes from product descriptions, product reviews, or specification tables so they can be used to help improve content and site usability, and reduce manual labour.
How are product attributes used?
Product attributes have two main functions in ecommerce. Firstly, they define a product’s features so users can search for them and filter down their search to the specifics. Filtered or faceted search systems, such as Elasticsearch, Solr, and Lucene, are great for this, and help reduce the decision paralysis that customers can otherwise experience when presented with a huge set of search results.
Secondly, product attributes can be used to generate product specification tables for use on Product Detail Pages or PDPs. Product specification tables make it much easier for customers to scan product page content and check the facts before they buy, which can increase product conversion rate, reduce telephone calls or live chats, and cut down the product return rate.
On some sites, product attributes are also shown as tags alongside reviews. For example, if you want to check whether a pair of headphones provides good bass, you can click the “bass” tag and you can filter the reviews by that attribute.
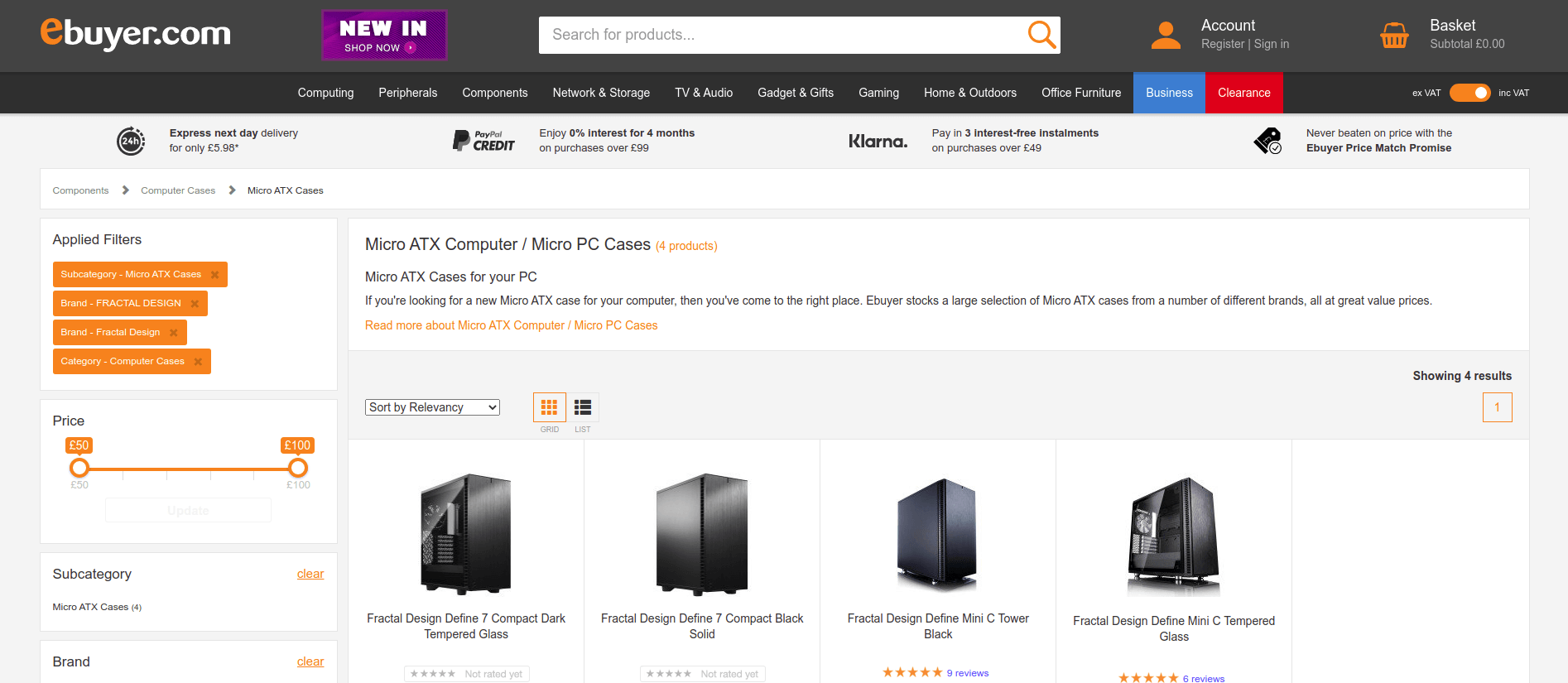 Consistency is critical when you’re faceting products with attributes.
Consistency is critical when you’re faceting products with attributes.
What happens if attributes are inconsistent?
Pretty much every ecommerce site has a level of inconsistency in its product attributes. Different writers may consider different attributes important; product set-up sheets may be missing key information; procurement teams or suppliers may be unwilling or unable to help fill in any gaps, and new attributes get added to some products and the others get out of sync.
This causes two issues. Firstly, when the missing attributes are important to the customers’ purchase decision process, they will either abandon the site or, if you’re lucky, contact with your customer service or sales team to find the missing information (which, of course, will rarely make its way back to the ecommerce team to prevent the same thing happening again).
Secondly, when product attributes are inconsistent across a product type, they cause the site search to only return a subset of the actual results. This can make customers think you don’t sell as many products as you do, because only some of them were labeled with the correct attributes, which usually causes them to abandon their search.
How do internet retailers manage product attributes?
Product attribute management is usually handled by a mixture of ecommerce copywriters or merchandisers. At the most basic level, they’ll define the required attributes for listing a product in a given category so these are obtained at the product set-up sheet point. They then ensure they get added correctly to the product before it is launched.
On larger sites, administrators may also create a custom attribute set to define each specific product type. For example, a graphics card will always require certain key fields to be populated before it can be published, thus ensuring search results always include every possible product as the attributes have to be applied consistently.
Periodically, ecommerce teams will go back over all the products in each category to audit the content and see if any further improvements can be made to the product attributes to improve specifications tables or aid search faceting.
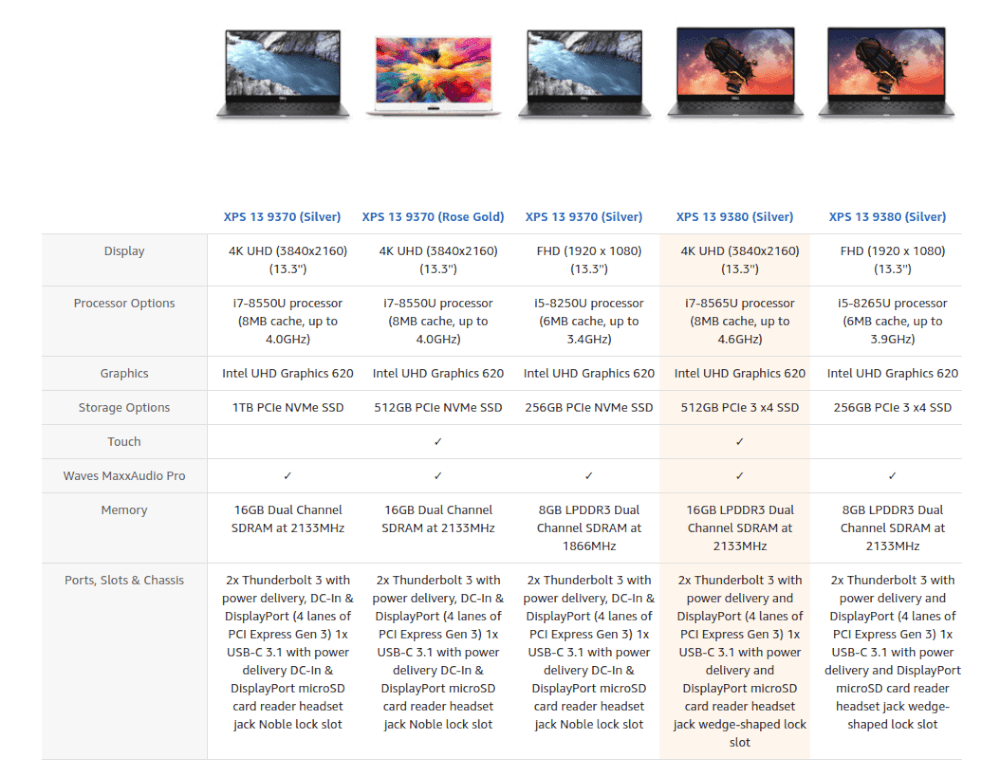 Product attributes put to good use on the Amazon website to allow product comparison.
Product attributes put to good use on the Amazon website to allow product comparison.
What happens on multi-seller sites or marketplaces?
Things are much harder on larger ecommerce sites or multi-seller sites or marketplaces, such as eBay, Amazon, AliExpress, Wish, or Rakuten. Here, product content is often being added by many different people (including third parties) and may span millions of products. It’s also added at scale and at speed, which makes it difficult to ensure product attributes are applied properly and consistently.
If these sites didn’t try to keep product attributes in good basic shape, customers would find the sites much harder to use, and the companies wouldn’t sell as much as they do. Perhaps unsurprisingly then, it is marketplaces and multi-seller ecommerce sites that have been at the forefront of Product Attribute Extraction research and adoption, along with the price comparison sites, such as Google Shopping, PriceGrabber, and ShopZilla.
eBay is a great example of a retailer emphasising the importance of product attributes to sellers using its platform. When you sell an item on eBay, it shows you the common product attributes used to describe products sold in that category and encourages you to fill them in.
Sell a hard disk for a computer and you’ll be asked to define its storage capacity (i.e. 5TB), interface (i.e. SATA III), type (i.e. Internal Desktop Drive), brand, and a whole range of other attributes that buyers want to use to find the exact product they’re looking for. Cleverly, it shows you an indicator of the number of searchers you’ll reach, so you can see your search visibility improving as you add additional attributes.
Even after you’ve added your product, eBay will encourage you to add more product attributes and sells the benefits of this really well. This helps you sell your item, and helps eBay generate more seller fees.
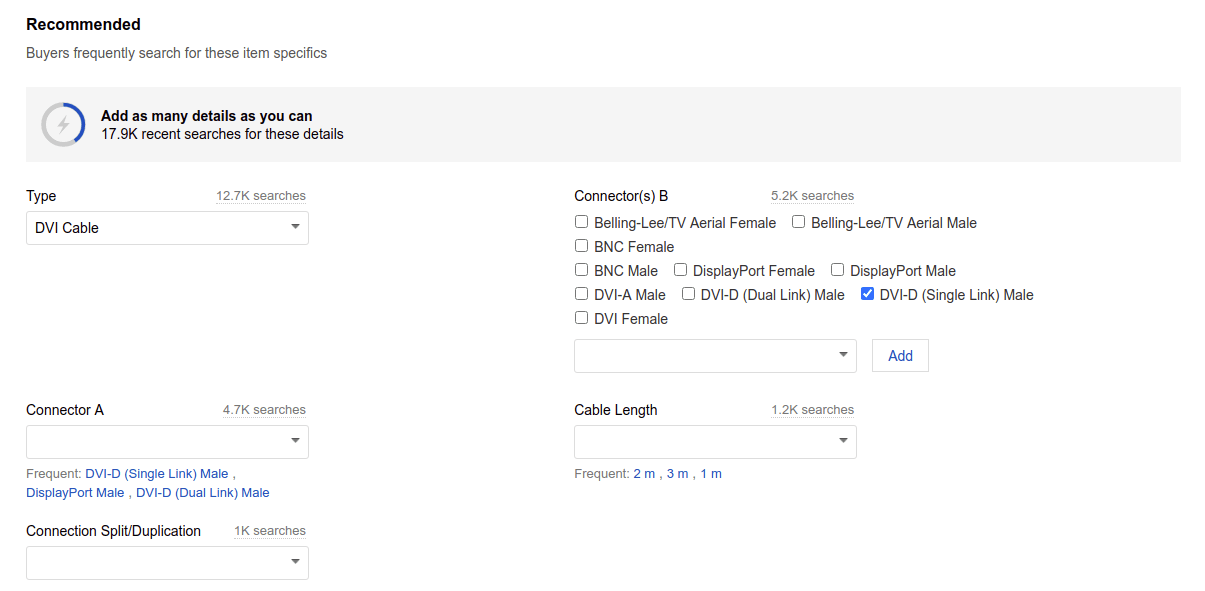 eBay encourages sellers to add attributes to their products.
eBay encourages sellers to add attributes to their products.
What practical applications does PAE have?
Product Attribute Extraction has been used for a range of things in ecommerce, all of which aim to improve the user experience, reduce manual labour, and increase conversion rate. Here are some of the common applications of this technology:
-
Extracting product attributes from product names or titles to improve search: Putthividhya and Hu (2011) describe the models they created at eBay to extract product attributes, such as the brand, from a short product title so the eBay platform could normalize incorrectly spelt product brand names and make them easier for customers to find.
-
Improving product catalog taxonomy on massive sites: Rezk et al. (2019) explained research undertaken by Rakuten (the Japanese equivalent of Amazon) to use PAE for improving their product catalog taxonomy on a dataset comprising over 200 million items, and to help provide a better view of the product range for category management purposes.
-
Extracting popular product attributes from product descriptions: Bing et al. (2016) created an unsupervised model that extracted popular product attributes from product descriptions using reviews to help identify the main points in which customers would be interested. These can then be highlighted in the product copy or advertising.
-
Examining product reviews to find the features that influence sales: Archak et. al. (2007) used a “hedonic regression” approach that examined product reviews and identified the product features that positively or negatively influenced product sales. The information from the model can be used to guide product designers on how to improve products, and help marketers identify the key features to highlight in content or advertising.
-
Extracting and classifying product attributes mentioned in reviews: Sun (2017) applied the Conditional Random Fields (CRF) model to extracting product attributes from reviews and then used a Support Vector Machine (SVM) to classify them to allow products to be evaluated using the attributes. This method could allow customers to view all reviews mentioning a particular product feature, such as fit or material.
-
Extracting attribute-value pairs from text for product comparison: Petrovski and Bizer (2017) describe a technique for extraction attribute-value pairs from both free-text fields and HTML product specification tables using DEXTER, so it can be used for product matching, product comparison, categorisation, and recommendations.
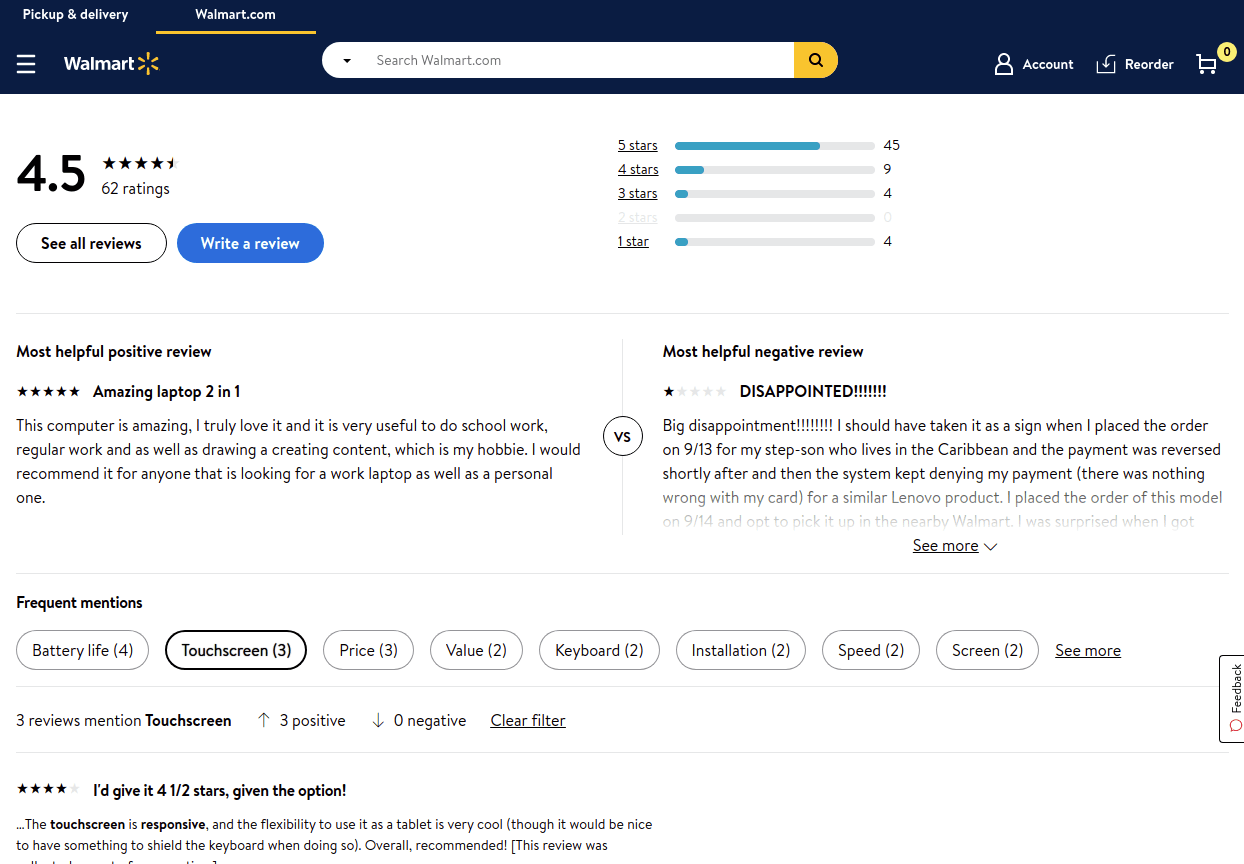 Product Attribute Extraction in use on Walmart’s website to help users sift through reviews.
Product Attribute Extraction in use on Walmart’s website to help users sift through reviews.
How is data pre-processed?
The usual processes are as with any other kind of NLP model: data is acquired, pre-processed, and tagged or annotated, prior to the modeling step. PAE pre-processing would typically follow a sequence like this:
-
Data acquisition: Product copy or review data is extracted from ecommerce websites, usually via scraping.
-
Tokenization: Words within the text documents are initially separated into a list of separate words using Tokenization or word segmentation.
-
PoS tagging: Part-of-Speech tagging, often via Brill’s PoS Tagger or Brill Tagger, is used to identify the type of each token, i.e. preposition, or noun.
-
Manual annotation: On supervised and semi-supervised learning models, additional tagging is undertaken manually. This is often a very laborious step. To generate annotated data, some scientists are now utilising schema.org microdata to speed up the process (see Ristoski et al., 2018).
What techniques are used for PAE?
To actually perform the attribute extraction a range of different techniques can be utilised. Here are some of those applied in recent papers on PAE:
-
Rule-based extraction: Rule-based techniques are sometimes used, but they’re not scalable and need to be written and maintained, making them unsuitable for most uses.
-
Bootstrapping: Bootstrapping (see Rezk et al., 2019) has recently been used by Rakuten to take a small or partly annotated set of initial training data and extend it by automatically tagging additional samples to increase the training data set size.
-
Noun Phrase Clustering: Noun Phrase Clustering techniques, such as the Group Average Agglomerative Clustering (GAAC) algorithm are used to compute clusters of related words.
-
N-gram analysis: N-gram analysis is used to identify unigrams, bigrams and trigrams. Some researchers have used specialised scoring functions to help identify the best N-gram to use.
-
Supervised text-based feature extraction: Dictionary-based approaches are often employed to create a lookup-list of attribute-value pairs within the data set, such as “colour-blue”, “storage-64gb”, from which others can be identified.
-
Unsupervised text-based feature extraction: Neural language modeling is used to extract text embeddings from structured product descriptions, such as schema markup. These normally use paragraph2vec, which is based on word2vec, and which utilises the Distributed Memory (DM) and Distributed Bag-of-Words (DBOW) models.

How do PAE models identify attributes?
Some models use ontology-based Named Entity Recognition (NER) to identify words from a source ontology containing the details of thousands of words. These work well on known terms in unstructured or structured documents, but are complex to manage.
Other models utilise deep learning to identify clusters or phrases using “word embedding”, which can understand the syntax and semantics of text. Once it’s been trained on the concepts of syntax and semantics, deep learning models are then able to spot similar trends in previously unseen data.
How is model accuracy assessed?
The usual metrics are used to measure performance: precision, recall, and F1 score.
| Precision | True Positives / (True Positives + False Positives) |
| Recall | True Positives / (True Positives + False Negatives) |
| F1 | (Precision x Recall) / (Precision + Recall) |
Which data sources are used?
Besides the product description, three semi-structured or structured data sources are also used for product attribute extraction, when available: Schema.org JSON-LD markup, HTML product specification tables, and HTML product specification lists.
The University of Mannheim in Germany is one of the leading institutes involved in PAE. They’ve created a data set called the Gold Standard for Product Matching and Product Feature Extraction, which includes a wide range of sources of structured data that can be used for training and testing models.
As you can see from their data below, the more structured the data the better. Schema.org markup outperforms the rest, which is why Google and other search engines are so keen for ecommerce retailers to embed it in their product pages.
Schema.org JSON-LD markup
| Category | Precision | Recall | F1 |
|---|---|---|---|
| Headphones | 0.623 | 0.588 | 0.604 |
| Phones | 0.601 | 0.452 | 0.515 |
| TVs | 0.573 | 0.604 | 0.590 |
HTML specification table data
| Category | Precision | Recall | F1 |
|---|---|---|---|
| Headphones | 0.579 | 0.614 | 0.596 |
| Phones | 0.443 | 0.555 | 0.493 |
| TVs | 0.521 | 0.658 | 0.581 |
Product specification list data
| Category | Precision | Recall | F1 |
|---|---|---|---|
| Headphones | 0.436 | 0.512 | 0.494 |
| Phones | 0.389 | 0.571 | 0.462 |
| TVs | 0.418 | 0.499 | 0.455 |
Why is schema.org markup so useful for training?
Depending on the retailer, schema.org JSON-LD markup can be an exceptionally rich source of data. The main benefit of it, of course, is that it’s structured. It’s also probable that the retailer providing it on their page will have taken time to ensure its accuracy, as their sales on ad platforms such as Bing Ads and Google Ads, depend on it.
Here’s an example of the Mobile Phones data set:
{
"id" : "19bbcbe4-5d36-43e0-9b23-e6a76e96f751",
"product_name" : "iphone 6 16gb",
"description" : "iphone 6 is perfect in every way. large, yet dramatically thin. powerful, but remarkably power efficient. with a smooth metal surface that seamlessly meets the retina hd display. it’s one continuous form where hardware and software function in perfect unison. developing an iphone with a larger, more advanced display meant pushing the edge of design. from the seamless transition of glass and metal to the streamlined profile, every detail was carefully considered to enhance your experience. so while its display is larger, iphone 6 feels just right. it's one thing to make a bigger display. it's something else entirely to make a bigger multitouch display with brilliant colors and higher contrast at even wider viewing angles. but that's exactly about the retina hd display. built on 64-bit desktop-class architecture, the a8 chip delivers more power, even while driving a larger display. the m8 motion coprocessor efficiently gathers data from advanced sensors and a barometer. and with increased battery life, iphone 6 lets you do more, for longer than ever. more people take more photos with iphone than with any other camera. and now the isight camera has a sensor with focus pixels and amazing video features, like 1080p hd at 60 fps, slo-mo at 240 fps, and time-lapse video mode. so you'll have more reasons to capture more moments on video, too. iphone 6 has faster lte download speeds, and it supports more lte bands than any other smartphone so you can roam in more places. and when connected to wi-fi, you'll get up to 3x faster speeds. the breakthrough touch id technology lets you securely access your iphone with the perfect password: your fingerprint.",
"ram" : "1gb",
"water_resistance" : false,
"memory" : "16gb",
"brand" : "apple",
"phone_type" : "iphone 6",
"computer_operating_system" : "ios 8",
"phone_carrier" : "verizon wireless",
"product_type" : "smartphone",
"core_count" : "null",
"processor_type":"a8",
"rear_cam_resolution" : "8 mp",
"front_cam_resolution" : "1.2 mp",
"color" : "space gray|silver|gold",
"wattage" : "",
"power_supply" : "",
"display_size" : "4.7 in",
"display_resolution" : "750 x 1334 pixels",
"voltage" : "1810 mah",
"mpn" : "mg5w2ll/a",
"modelnum" : "",
"width" : "2.6 in",
"height" : "5.4 in",
"depth" : "0.3 in",
"weight" : "6.1oz",
"dimensions" : "138.1 x 67 x 6.9 mm",
"body_material" : "stainless steel, glass, anodized aluminum",
"package_height" : "",
"product_code" : "",
"product_gtin" : "00885909950928",
"manufacturer" : "",
"urls" : [ {
"value" : "https://www.google.com/shopping/product/1989366282910426913/specs?hl=en&q=iphone+6+16+gb&sa=x&ved=0ahukewjl-pqj1zdlahudeg8khyodcg0q6iqi3ae"
}, {
"value" : "http://www.gsmarena.com/apple_iphone_6-6378.php"
} ]
}
For more information on scraping JSON-LD schema.org markup from your competitors’ websites, check out my tutorial which shows how you can do this using Selenium and Extruct.
Further reading
-
Archak, N., Ghose, A. and Ipeirotis, P.G., 2007, August. Show me the money! Deriving the pricing power of product features by mining consumer reviews. In Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 56-65).
-
Bing, L., Wong, T.L. and Lam, W., 2016. Unsupervised extraction of popular product attributes from ecommerce web sites by considering customer reviews. ACM Transactions on Internet Technology (TOIT), 16(2), pp.1-17.
-
Putthividhya, D. and Hu, J., 2011, July. Bootstrapped named entity recognition for product attribute extraction. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (pp. 1557-1567).
-
Petrovski, P., Bryl, V. and Bizer, C., 2014, October. Learning Regular Expressions for the Extraction of Product Attributes from Ecommerce Microdata. In LD4IE@ ISWC (pp. 43-54).
-
Petrovski, P. and Bizer, C., 2017, August. Extracting attribute-value pairs from product specifications on the web. In Proceedings of the International Conference on Web Intelligence (pp. 558-565).
-
Raju, S., Shishtla, P. and Varma, V., 2009, December. A Graph Clustering Approach to Product Attribute Extraction. In IICAI (pp. 1438-1447).
-
Rezk, M., Alemany, L.A., Nio, L. and Zhang, T., 2019, April. Accurate Product Attribute Extraction on the Field. In 2019 IEEE 35th International Conference on Data Engineering (ICDE) (pp. 1862-1873). IEEE.
-
Ristoski, P., Petrovski, P., Mika, P. and Paulheim, H., 2018. A machine learning approach for product matching and categorization. Semantic web, 9(5), pp.707-728.
-
Sun, L., 2017, December. Research on Product Attribute Extraction and Classification Method for Online Review. In 2017 International Conference on Industrial Informatics-Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII) (pp. 117-121). IEEE.
-
Qiu, D., Barbosa, L., Dong, X.L., Shen, Y. and Srivastava, D., 2015. Dexter: large-scale discovery and extraction of product specifications on the web. Proceedings of the VLDB Endowment, 8(13), pp.2194-2205.
Matt Clarke, Wednesday, March 03, 2021













Other posts you might like

How to tune a LightGBMClassifier model with Optuna
The LightGBM model is a gradient boosting framework that uses tree-based learning algorithms, much like the popular XGBoost model. LightGBM supports both classification and regression tasks, and is known for...

How to create a customer retention model with XGBoost
Although all business know the importance of retaining customers, few companies are actually able to measure customer retention accurately, and fewer still can predict which ones will churn or be...
