How to do custom Named Entity Recognition in Pandas using Spacy
Learn how to use perform custom named entity recognition in Pandas with Spacy by analysing the skills employers are looking for in job advertisements.

As I showed in my previous tutorial on named entity recognition in Spacy, the EntityRuler allows you to customise Spacy’s default NER model to allow you to create your own named entities based on pattern matching.
In this tutorial I’ll show you how to create a custom NER model to extract the skills from data science jobs using a dataset I scraped from all the UK’s current data science roles.
We’ll import the dataset into Pandas, create a custom NER model to extract the skills from the job ads, use the named entities to clean the dataset, and then analyse the skills employers are currently looking for, and the salaries they’re currently paying.
Import the packages
To get started, open a Jupyter notebook and import Spacy. If you don’t have Spacy installed, you can install it from the Pip package management system by entering pip3 install spacy. We’ll use the Pandas set_option() method to increase the maximum number of rows shown, so we can scan more data.
import pandas as pd
import spacy
pd.set_option('display.max_rows', 200)
Load the data
Next, we’ll load my data science jobs dataset. I created this using a custom web scraper written in Requests-HTML that scraped all the current data science related jobs from the Reed jobs website. The dataset includes all the information on the job, including the job title, salary, location, and the job description itself.
df = pd.read_csv('https://raw.githubusercontent.com/flyandlure/datasets/master/data_science_jobs.csv')
df.sample(1).T
| 398 | |
|---|---|
| reference | 41642346 |
| title | Data Engineering Tech Lead |
| date_posted | 2020-12-27 |
| date_ending | 2021-02-07T23:55:00.0000000 |
| advertiser | Definitive Recruitment Ltd |
| location | Middlesex |
| city | Uxbridge |
| country | GB |
| salary | 75000.0 |
| salary_min | 75000.0 |
| salary_max | 80000.0 |
| salary_frequency | YEAR |
| salary_currency | NaN |
| description | Apply now\nThe role involves technical leaders... |
Use Spacy load() to import a model
Next, we need load a model into Spacy. There are various models you can use. I’m using the en_core_web_sm model. To download the model you will first need to run a Python command to fetch the latest model and then use the Spacy load() method to load it.
python -m spacy download en_core_web_sm
nlp = spacy.load('en_core_web_sm')
Create EntityRuler pattern matching rules
Now we need to create the rules to pass to Spacy’s EntityRuler. These will power our custom named entity recognition system and will look for pattern matches in the job description, assign a label to them called SKILL, and allow us to extract the named entities.
To create the list of patterns to match, I scoured the job ads to look for skills mentioned in the posts until I stopped getting much improvement on the numbers of skills extracted.
This likely doesn’t cover every skill mentioned in data science job ads, but it definitely catches the bulk of the technical ones. You can easily extend it to cover other areas, or soft skills, such as “stakeholder management”.
skills = [
{'label': 'SKILL', 'pattern': [{"LOWER": "python"}], 'id': 'python'},
{'label': 'SKILL', 'pattern': [{"LOWER": "r"}], 'id': 'r'},
{'label': 'SKILL', 'pattern': [{"LOWER": "sas"}], 'id': 'sas'},
{'label': 'SKILL', 'pattern': [{"LOWER": "java"}], 'id': 'java'},
{'label': 'SKILL', 'pattern': [{"LOWER": "c++"}], 'id': 'c++'},
{'label': 'SKILL', 'pattern': [{"LOWER": "c#"}], 'id': 'c#'},
{'label': 'SKILL', 'pattern': [{"LOWER": "c"}], 'id': 'c'},
{'label': 'SKILL', 'pattern': [{"LOWER": "javascript"}], 'id': 'javascript'},
{'label': 'SKILL', 'pattern': [{"LOWER": "html"}], 'id': 'html'},
{'label': 'SKILL', 'pattern': [{"LOWER": "css"}], 'id': 'css'},
{'label': 'SKILL', 'pattern': [{"LOWER": "php"}], 'id': 'php'},
{'label': 'SKILL', 'pattern': [{"LOWER": "ruby"}], 'id': 'ruby'},
{'label': 'SKILL', 'pattern': [{"LOWER": "scala"}], 'id': 'scala'},
{'label': 'SKILL', 'pattern': [{"LOWER": "perl"}], 'id': 'perl'},
{'label': 'SKILL', 'pattern': [{"LOWER": "matlab"}], 'id': 'matlab'},
{'label': 'SKILL', 'pattern': [{"LOWER": "hadoop"}], 'id': 'hadoop'},
{'label': 'SKILL', 'pattern': [{"LOWER": "spark"}], 'id': 'spark'},
{'label': 'SKILL', 'pattern': [{"LOWER": "hive"}], 'id': 'hive'},
{'label': 'SKILL', 'pattern': [{"LOWER": "pig"}], 'id': 'pig'},
{'label': 'SKILL', 'pattern': [{"LOWER": "shark"}], 'id': 'shark'},
{'label': 'SKILL', 'pattern': [{"LOWER": "oozie"}], 'id': 'oozie'},
{'label': 'SKILL', 'pattern': [{"LOWER": "zookeeper"}], 'id': 'zookeeper'},
{'label': 'SKILL', 'pattern': [{"LOWER": "flume"}], 'id': 'flume'},
{'label': 'SKILL', 'pattern': [{"LOWER": "mahout"}], 'id': 'mahout'},
{'label': 'SKILL', 'pattern': [{"LOWER": "sqoop"}], 'id': 'sqoop'},
{'label': 'SKILL', 'pattern': [{"LOWER": "storm"}], 'id': 'storm'},
{'label': 'SKILL', 'pattern': [{"LOWER": "kafka"}], 'id': 'kafka'},
{'label': 'SKILL', 'pattern': [{"LOWER": "cassandra"}], 'id': 'cassandra'},
{'label': 'SKILL', 'pattern': [{"LOWER": "mongodb"}], 'id': 'mongodb'},
{'label': 'SKILL', 'pattern': [{"LOWER": "redis"}], 'id': 'redis'},
{'label': 'SKILL', 'pattern': [{"LOWER": "elasticsearch"}], 'id': 'elasticsearch'},
{'label': 'SKILL', 'pattern': [{"LOWER": "neo4j"}], 'id': 'neo4j'},
{'label': 'SKILL', 'pattern': [{"LOWER": "sql"}], 'id': 'sql'},
{'label': 'SKILL', 'pattern': [{"LOWER": "nosql"}], 'id': 'nosql'},
{'label': 'SKILL', 'pattern': [{"LOWER": "postgresql"}], 'id': 'postgresql'},
{'label': 'SKILL', 'pattern': [{"LOWER": "oracle"}], 'id': 'oracle'},
{'label': 'SKILL', 'pattern': [{"LOWER": "mysql"}], 'id': 'mysql'},
{'label': 'SKILL', 'pattern': [{"LOWER": "sqlite"}], 'id': 'sqlite'},
{'label': 'SKILL', 'pattern': [{"LOWER": "mariadb"}], 'id': 'mariadb'},
{'label': 'SKILL', 'pattern': [{"LOWER": "mssql"}], 'id': 'mssql'},
{'label': 'SKILL', 'pattern': [{"LOWER": "db2"}], 'id': 'db2'},
{'label': 'SKILL', 'pattern': [{"LOWER": "pandas"}], 'id': 'pandas'},
{'label': 'SKILL', 'pattern': [{"LOWER": "spacy"}], 'id': 'spacy'},
{'label': 'SKILL', 'pattern': [{"LOWER": "nltk"}], 'id': 'nltk'},
{'label': 'SKILL', 'pattern': [{"LOWER": "gensim"}], 'id': 'gensim'},
{'label': 'SKILL', 'pattern': [{"LOWER": "huggingface"}], 'id': 'huggingface'},
{'label': 'SKILL', 'pattern': [{"LOWER": "transformers"}], 'id': 'transformers'},
{'label': 'SKILL', 'pattern': [{"LOWER": "scikit-learn"}], 'id': 'scikit-learn'},
{'label': 'SKILL', 'pattern': [{"LOWER": "scikit"}, {"LOWER": "learn"}], 'id': 'scikit-learn'},
{'label': 'SKILL', 'pattern': [{"LOWER": "sklearn"}], 'id': 'scikit-learn'},
{'label': 'SKILL', 'pattern': [{"LOWER": "tensor"}, {"LOWER": "flow"}], 'id': 'tensorflow'},
{'label': 'SKILL', 'pattern': [{"LOWER": "tensorflow"}], 'id': 'tensorflow'},
{'label': 'SKILL', 'pattern': [{"LOWER": "keras"}], 'id': 'keras'},
{'label': 'SKILL', 'pattern': [{"LOWER": "pytorch"}], 'id': 'pytorch'},
{'label': 'SKILL', 'pattern': [{"LOWER": "numpy"}], 'id': 'numpy'},
{'label': 'SKILL', 'pattern': [{"LOWER": "scipy"}], 'id': 'scipy'},
{'label': 'SKILL', 'pattern': [{"LOWER": "matplotlib"}], 'id': 'matplotlib'},
{'label': 'SKILL', 'pattern': [{"LOWER": "seaborn"}], 'id': 'seaborn'},
{'label': 'SKILL', 'pattern': [{"LOWER": "plotly"}], 'id': 'plotly'},
{'label': 'SKILL', 'pattern': [{"LOWER": "bokeh"}], 'id': 'bokeh'},
{'label': 'SKILL', 'pattern': [{"LOWER": "d3"}], 'id': 'd3'},
{'label': 'SKILL', 'pattern': [{"LOWER": "airflow"}], 'id': 'airflow'},
{'label': 'SKILL', 'pattern': [{"LOWER": "docker"}], 'id': 'docker'},
{'label': 'SKILL', 'pattern': [{"LOWER": "kubernetes"}], 'id': 'kubernetes'},
{'label': 'SKILL', 'pattern': [{"LOWER": "aws"}], 'id': 'aws'},
{'label': 'SKILL', 'pattern': [{"LOWER": "amazon"}, {"LOWER": "web"}, {"LOWER": "services"}], 'id': 'aws'},
{'label': 'SKILL', 'pattern': [{"LOWER": "gcp"}], 'id': 'gcp'},
{'label': 'SKILL', 'pattern': [{"LOWER": "google"}, {"LOWER": "cloud"}, {"LOWER": "platform"}], 'id': 'gcp'},
{'label': 'SKILL', 'pattern': [{"LOWER": "azure"}], 'id': 'azure'},
{'label': 'SKILL', 'pattern': [{"LOWER": "machine learning"}], 'id': 'machine learning'},
{'label': 'SKILL', 'pattern': [{"LOWER": "ml"}], 'id': 'machine learning'},
{'label': 'SKILL', 'pattern': [{"LOWER": "deep"}, {"LOWER": "learning"}], 'id': 'deep learning'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dl"}], 'id': 'deep learning'},
{'label': 'SKILL', 'pattern': [{"LOWER": "natural"}, {"LOWER": "language"}, {"LOWER": "processing"}], 'id': 'nlp'},
{'label': 'SKILL', 'pattern': [{"LOWER": "nlp"}], 'id': 'nlp'},
{'label': 'SKILL', 'pattern': [{"LOWER": "computer"}, {"LOWER": "vision"}], 'id': 'computer vision'},
{'label': 'SKILL', 'pattern': [{"LOWER": "cv"}], 'id': 'computer vision'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "science"}], 'id': 'data science'},
{'label': 'SKILL', 'pattern': [{"LOWER": "ds"}], 'id': 'data science'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "analysis"}], 'id': 'data analysis'},
{'label': 'SKILL', 'pattern': [{"LOWER": "da"}], 'id': 'data analysis'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "visualisation"}], 'id': 'data visualisation'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "visualization"}], 'id': 'data visualization'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dv"}], 'id': 'data visualisation'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "mining"}], 'id': 'data mining'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dm"}], 'id': 'data mining'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "engineering"}], 'id': 'data engineering'},
{'label': 'SKILL', 'pattern': [{"LOWER": "de"}], 'id': 'data engineering'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "analytics"}], 'id': 'data analytics'},
{'label': 'SKILL', 'pattern': [{"LOWER": "da"}], 'id': 'data analytics'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "warehouse"}], 'id': 'data warehouse'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dw"}], 'id': 'data warehouse'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "pipelines"}], 'id': 'data pipelines'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dp"}], 'id': 'data pipelines'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "munging"}], 'id': 'data munging'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dm"}], 'id': 'data munging'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "preparation"}], 'id': 'data preparation'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dp"}], 'id': 'data preparation'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "wrangling"}], 'id': 'data wrangling'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dw"}], 'id': 'data wrangling'},
{'label': 'SKILL', 'pattern': [{"LOWER": "data"}, {"LOWER": "cleaning"}], 'id': 'data cleaning'},
{'label': 'SKILL', 'pattern': [{"LOWER": "dc"}], 'id': 'data cleaning'},
]
Next you need to pass the huge list of patterns to the add_pipe() method and use before='ner' to ensure that Spacy overwrites any default named entities with the new SKILL entities. The patterns are then added to the ruler using add_patterns().
ruler = nlp.add_pipe('entity_ruler', before='ner')
ruler.add_patterns(skills)
Extract the skills to a new column
To run the custom named entity recognition model on our entire Pandas dataframe we can use the Pandas apply() method and a lambda function. We’ll create a for loop that loops over the entities and returns those where the label_ is SKILL.
The ent.text value contains the matched words, i.e. Python or MySQL, but we actually want the ent.ent_id_ value, since this will ensure all the values are equal, and we don’t have to deal with “scikit-learn”, “scikit learn” and “sklearn” when analysing the results.
Finally, we can use another lambda function to use set() to de-duplicate the values and return only the unique matches in a Python list. We get back a single column in our dataframe containing the SKILL named entities extracted.
df['skills'] = df['description'].apply(lambda x: [ent.ent_id_ for ent in nlp(x).ents if ent.label_ == 'SKILL'])
df['skills'] = df['skills'].apply(lambda x: list(set(x)))
df[['title', 'skills']].sample(5)
| title | skills | |
|---|---|---|
| 406 | Data Science Consultant | [sql, hadoop, python, scala, spark, data scien... |
| 47 | Senior Data Scientist - 5 Months FTC | [python, spark, data science, computer vision,... |
| 117 | Data Scientist - Life Sciences | [data science] |
| 298 | Backend Developer - Remote | [sql, nlp, python, computer vision, data scien... |
| 3 | Data Science Consultant | [data science, r, python] |
Use the named entities to clean the dataset
Now we’ve analysed each job description and extracted the named entities for job skills to a separate column we need to check the cleanliness of the data. Since recruiters often post job ads in the wrong places, some jobs filed under “data science”, might not truly be data science roles, so we can use the skills column to identify these.
df[['title', 'skills']].sort_values('skills', key=lambda x: x.str.len(), ascending=True).head(100)
| title | skills | |
|---|---|---|
| 251 | Risk and Pricing Quant Lead | [] |
| 186 | Data Scientist InsurTech | [data science] |
| 35 | Data Science and Analytics Specialist - Data S... | [data science] |
| 39 | Data Scientist / Statistician (PhD level) | [data science] |
| 41 | Lead Data Scientist Manager Reading, Halifax o... | [data science] |
| 340 | UI Lead Designer / UX Lead Designer | [data science] |
| 381 | Account Manager - FinTech | [data science] |
| 383 | Graduate Recruitment Consultant | [data science] |
| 384 | Data Quality Manager | [data science] |
| 312 | Recruitment Consultant | [data science] |
| 387 | Data Scientist | [data science] |
| 593 | Principal UX Designer | [data engineering] |
| 66 | Senior Data Scientist | [data science] |
| 268 | Recruitment Consultant | [data science] |
| 72 | Lead Data Scientist Manager Reading, Halifax o... | [data science] |
| 267 | Credit Risk Manager - Credit Cards | [data science] |
| 260 | Security Architect - Active SC clearance required | [data science] |
| 494 | Sales Development Representative - SaaS Solutions | [data engineering] |
| 535 | Project Systems Engineer | [data engineering] |
| 100 | Sales Development Representative in Gaming | [data science] |
| 196 | Trainee Recruitment Consultant - Gaming & Data | [data science] |
| 184 | Recruitment Consultant - Twickenham | [data science] |
| 177 | Senior Pricing Price Analyst | [data science] |
| 105 | Technology Recruitment Consultant | [data science] |
| 107 | Insights Consultancy Director / Applied Scienc... | [data science] |
| 113 | Product Manager | [data science] |
| 117 | Data Scientist - Life Sciences | [data science] |
| 159 | Recruitment Consultant - Life Sciences | [data science] |
| 158 | Recruitment Consultant - Risk & Quantitative F... | [data science] |
| 157 | Product Manager - B2B Software | [data science] |
| 143 | Account Manager | [data science] |
| 34 | Data Science and Analytics Specialist - Data S... | [data science] |
| 33 | Senior Data Science Recruiter - Team Leader Op... | [data science] |
| 140 | Director - Customer Marketing Analytics & Stra... | [data science] |
| 378 | Senior Digital Strategist | [data science] |
| 1 | Data Science Recruiter | [data science] |
| 590 | Data Platforms Lead | [data engineering] |
| 352 | Enterprise Business Development Manager - Benelux | [data science] |
| 592 | Business Analyst | [data engineering] |
| 376 | Senior Data Strategist - CRM & Digital | [data science] |
| 27 | Team Leader - Data Science Recruitment | [data science] |
| 364 | Senior Product Manager | [data science] |
| 31 | Business Development Manager - Data Science & ... | [data science, c] |
| 92 | Data Scientist All Levels | [data science, computer vision] |
| 218 | Software Engineer - Java | [data science, java] |
| 219 | BDR Manager/Sales Manager | [data science, data analytics] |
| 32 | Business Development Manager - Data Science & ... | [data science, c] |
| 208 | Senior Data Scientist | [sql, computer vision] |
| 375 | Commercial Finance Manager / FP&A Analyst SaaS... | [data science, c] |
| 247 | Senior Data Analyst | [data science, data mining] |
| 15 | Data Science Lead (Pricing) | [data science, computer vision] |
| 252 | Agile Business Analyst | [data science, c] |
| 16 | Data Science Lead (Pricing) | [data science, computer vision] |
| 87 | Insight Analyst | [data science, sql] |
| 206 | KDB Developer | [data science, java] |
| 374 | Population Health Consultant Lead | [sql, data science] |
| 198 | Director of Data | [data science, computer vision] |
| 11 | Data Science Lead (Pricing) | [data science, computer vision] |
| 10 | Data Science Lead (Pricing) | [data science, computer vision] |
| 591 | JavaScript Developer - True Microservices/Node... | [data engineering, python] |
| 174 | Sales Account Manager - Data & Analytics | [data science, c] |
| 7 | Head of Data Science | [data science, computer vision] |
| 110 | Senior Insight Analyst | [sql, data science] |
| 111 | Senior Insight Analyst | [sql, data science] |
| 170 | Senior Business Development Manager | [data science, c] |
| 168 | Product Manager | [data science, computer vision] |
| 118 | Senior Product Manager - B2C | [data science, data analysis] |
| 149 | Senior Data Scientist | [computer vision, python] |
| 577 | Marketing Solutions Senior IT Project Manager ... | [data engineering, c] |
| 203 | Data Scientist | [spark, data science] |
| 361 | Head of Analytics | [data science, python] |
| 536 | Senior Data Analyst - Oxford | [data engineering, data analytics] |
| 279 | Senior Recruitment Consultant: Technology | [data science, computer vision] |
| 345 | Senior BI Analyst | [data science, data analysis] |
| 29 | Resourcer - Data, Analytics & Data Science | [data science, computer vision] |
| 28 | Product Manager - Data Science Routing | [data science, computer vision] |
| 336 | Agile Business Analyst - Public Sector | [data science, data visualisation] |
| 26 | Director of Data Science and Decision Science | [data science, computer vision] |
| 330 | Data Engineer | [data science, python] |
| 19 | Head of Data Science and Analytics | [data science, computer vision] |
| 320 | Senior Agile Business Analyst - Public Sector | [data science, data visualisation] |
| 319 | Agile Business Analyst - Public Sector | [data science, data visualisation] |
| 316 | Senior Data Analytics Recruitment Consultant | [data science, data analytics] |
| 589 | Mid Level JavaScript Developer -Microservices/... | [data engineering, python] |
| 385 | Head of Strategic Environment | [data science, data analysis] |
| 22 | Head of Data Science - FinTech | [data science, computer vision] |
| 355 | Platform Technical Lead | [data science, azure] |
| 282 | Infrastructure Engineer - Active DV Clearance ... | [data science, data visualisation] |
| 359 | Population Health Consultant Lead | [sql, data science] |
| 67 | Data Scientist/ Senior Data Scientist | [data science, computer vision] |
| 474 | Head of Software Development | [data engineering, azure] |
| 294 | Technical Business Analyst / Scrum Master - Te... | [data science, data analysis] |
| 388 | Corporate Information Analyst | [data science, r, sql] |
| 367 | Oracle DBA | [data science, data visualisation, oracle] |
| 413 | Lead Data Engineer - SSIS, ETL, SQL | [data engineering, sql, oracle] |
| 453 | Product Analyst | [data engineering, sql, computer vision] |
| 455 | Senior Data Engineer | [data engineering, kafka, data pipelines] |
| 341 | Junior Software Developer | [data science, c, javascript] |
| 401 | Data Engineering Lead - Azure | [data engineering, azure, sql] |
| 457 | Lead Data Engineer - SSIS, ETL, SQL | [data engineering, sql, oracle] |
For a start, we can drop the very few rows present that don’t have any skills detected, since they’re unlikely to be data science roles. We can also eyeball the list above to look for other keywords that might denote non-data science roles. For example, “recruiter” or “dba”.
# Drop rows with no skills
df = df[df['skills'].str.len() > 0]
We’ll create a list of keywords that appear in the non-data science roles and we’ll filter the dataframe to exclude those rows that include one of the words in the job title. This cleans up a good chunk of the less relevant role titles that could have added noise to our data.
# Drop rows with one of the following strings in the job title
titles = ['recruit', 'resourcer', 'software engineer', 'health', 'product manager',
'ux', 'sales', 'business development', 'account manager', 'risk manager', 'kdb',
'business analyst', 'javascript', 'security', 'data quality', 'finance manager',
'software development', 'project manager', 'dba', 'product analyst', 'pricing analyst',
'crm', 'java', 'agile', 'product owner', 'it director', 'software developer']
df = df[~df['title'].str.contains('|'.join(titles), case=False)]
Re-querying the dataframe to show the rows with the lowest number of matched skills first shows that we’ve now removed most of the less relevant roles, leaving only the true data science positions behind. Of course, if you wanted to put this into production, you could fully automate this step by creating a Naive Bayes text classification model to determine how to classify each role type.
df[['title', 'skills']].sort_values('skills', key=lambda x: x.str.len(), ascending=True).head(100)
| title | skills | |
|---|---|---|
| 140 | Director - Customer Marketing Analytics & Stra... | [data science] |
| 66 | Senior Data Scientist | [data science] |
| 387 | Data Scientist | [data science] |
| 186 | Data Scientist InsurTech | [data science] |
| 378 | Senior Digital Strategist | [data science] |
| 590 | Data Platforms Lead | [data engineering] |
| 107 | Insights Consultancy Director / Applied Scienc... | [data science] |
| 39 | Data Scientist / Statistician (PhD level) | [data science] |
| 35 | Data Science and Analytics Specialist - Data S... | [data science] |
| 34 | Data Science and Analytics Specialist - Data S... | [data science] |
| 535 | Project Systems Engineer | [data engineering] |
| 117 | Data Scientist - Life Sciences | [data science] |
| 177 | Senior Pricing Price Analyst | [data science] |
| 41 | Lead Data Scientist Manager Reading, Halifax o... | [data science] |
| 72 | Lead Data Scientist Manager Reading, Halifax o... | [data science] |
| 67 | Data Scientist/ Senior Data Scientist | [data science, computer vision] |
| 247 | Senior Data Analyst | [data science, data mining] |
| 208 | Senior Data Scientist | [sql, computer vision] |
| 87 | Insight Analyst | [data science, sql] |
| 203 | Data Scientist | [spark, data science] |
| 149 | Senior Data Scientist | [computer vision, python] |
| 92 | Data Scientist All Levels | [data science, computer vision] |
| 385 | Head of Strategic Environment | [data science, data analysis] |
| 198 | Director of Data | [data science, computer vision] |
| 536 | Senior Data Analyst - Oxford | [data engineering, data analytics] |
| 15 | Data Science Lead (Pricing) | [data science, computer vision] |
| 345 | Senior BI Analyst | [data science, data analysis] |
| 330 | Data Engineer | [data science, python] |
| 7 | Head of Data Science | [data science, computer vision] |
| 282 | Infrastructure Engineer - Active DV Clearance ... | [data science, data visualisation] |
| 16 | Data Science Lead (Pricing) | [data science, computer vision] |
| 22 | Head of Data Science - FinTech | [data science, computer vision] |
| 355 | Platform Technical Lead | [data science, azure] |
| 361 | Head of Analytics | [data science, python] |
| 11 | Data Science Lead (Pricing) | [data science, computer vision] |
| 111 | Senior Insight Analyst | [sql, data science] |
| 10 | Data Science Lead (Pricing) | [data science, computer vision] |
| 26 | Director of Data Science and Decision Science | [data science, computer vision] |
| 19 | Head of Data Science and Analytics | [data science, computer vision] |
| 110 | Senior Insight Analyst | [sql, data science] |
| 560 | Data and Analytics Delivery Manager | [data engineering, data warehouse, data analysis] |
| 209 | Data Engineer | [data science, java, python] |
| 214 | Senior Research Scientist | [machine learning, data science, computer vision] |
| 450 | Data Engineer Azure, SQL Nottingham Circa £60k | [data engineering, azure, sql] |
| 172 | Data Scientist | [data science, nosql, python] |
| 79 | Junior Data Scientist | [data science, python, sql] |
| 401 | Data Engineering Lead - Azure | [data engineering, azure, sql] |
| 74 | Junior Data Scientist | [data science, python, sql] |
| 215 | Senior Research Scientist | [machine learning, data science, computer vision] |
| 123 | Lead Data Scientist | [machine learning, data science, computer vision] |
| 73 | Data Scientist | [data science, python, sql] |
| 114 | Customer Analytics Manager Remote | [data science, python, sql] |
| 413 | Lead Data Engineer - SSIS, ETL, SQL | [data engineering, sql, oracle] |
| 414 | Clojure Developer Remote | [data engineering, javascript, aws] |
| 423 | Mid Level Data Engineer | [data engineering, sql, python] |
| 457 | Lead Data Engineer - SSIS, ETL, SQL | [data engineering, sql, oracle] |
| 152 | Senior Data Scientist | [data science, r, python] |
| 104 | Senior Data Scientist | [data science, python, sql] |
| 125 | Customer Analytics Manager Remote | [data science, python, sql] |
| 572 | Snowflake Data Engineer | [data engineering, sql, data science] |
| 531 | Data Architect - Remote | [data engineering, data science, aws] |
| 88 | Data Scientist Investment | [machine learning, data science, computer vision] |
| 455 | Senior Data Engineer | [data engineering, kafka, data pipelines] |
| 343 | Senior Digital Media Insight Analyst | [data science, data visualisation, sql] |
| 58 | Data & Decision Science Director | [data science, c, computer vision] |
| 388 | Corporate Information Analyst | [data science, r, sql] |
| 486 | Cloud Data Developer | [data engineering, sql, azure] |
| 497 | Digital Analytics Lead - Fully Remote Working | [data engineering, data science, computer vision] |
| 3 | Data Science Consultant | [data science, r, python] |
| 65 | Junior Python Developer | [data science, python, computer vision] |
| 4 | Data Science Manager | [data science, data analytics, computer vision] |
| 332 | Technical Pricing and Data Analyst London Market | [sql, data science, data visualisation] |
| 500 | SQL Consultant | [data engineering, sql, azure] |
| 14 | Lead Data Science Consultant | [machine learning, data science, computer vision] |
| 180 | Senior Data Scientist - Quant | [data science, r, python, sql] |
| 307 | Head of Engineering. Global Startup. Big Data | [spark, data science, hadoop, airflow] |
| 303 | Scala Data Engineer | [aws, java, data science, scala] |
| 179 | Senior Data Scientist | [data science, python, computer vision, sql] |
| 310 | Bioinformatician | [data science, r, python, aws] |
| 311 | Computational Biologist | [data science, r, python, aws] |
| 302 | Senior C++ Developer - 12 Mth FTC | [c++, c, data science, python] |
| 176 | C#/.NET Developer | [data science, c, azure, javascript] |
| 317 | BI Analyst | [sql, data science, data visualisation, comput... |
| 228 | Senior Research Data Scientist | [data science, python, computer vision, sql] |
| 325 | Data Visualisation Analyst | [data science, data visualisation, computer vi... |
| 301 | Senior C++ Developer 12 month FTC | [c++, c, data science, python] |
| 326 | Senior Media Effectiveness Analyst | [sql, data visualisation, data science, python] |
| 434 | Data Engineer | [data engineering, sql, data pipelines, comput... |
| 438 | Data Engineer | [data engineering, sql, data science, azure] |
| 444 | Data Engineer | [data engineering, sql, data pipelines, comput... |
| 146 | Senior Analyst - Strategy £40-55k + Bens | [data science, r, python, sql] |
| 145 | Market Research Data Scientist | [data science, r, python, sql] |
| 144 | Data Scientist - Gaming/ Betting | [data science, azure, python, computer vision] |
| 142 | Senior DevOps Engineer | [data science, aws, python, computer vision] |
| 324 | Lead Developer, Python, Data Scientist, AI, CN... | [computer vision, pytorch, data science, python] |
| 353 | Senior Analyst - Marketing Effectiveness / Eco... | [data science, r, python, sql] |
| 274 | Research Data Scientist | [data science, python, computer vision, sql] |
| 377 | Data Scientist - Renewable Energy / Financial ... | [sql, data science, r, python] |
| 225 | Front End Developer | [data science, css, javascript, azure] |
| 224 | Head of Data / Data Lead - Well-funded Scaleup | [data science, r, python, sql] |
Remove outliers
Before we analyse the data, we need to check for potential outliers caused by job posters adding the wrong salary to their positions. We can do this easily by using the Pandas head() and tail() functions after sorting the dataframe by salary. It shows that one row needs to be corrected because it’s got a zero missing - the salary for the role should actually be £100,000 not £10,000.
df[['title', 'salary']].sort_values('salary', ascending=True).head()
| title | salary | |
|---|---|---|
| 132 | Senior Customer Insight Analytics Manager | 10000.0 |
| 362 | Graduate Analytics Positions | 20000.0 |
| 164 | Data Analyst Apprentice | 22000.0 |
| 79 | Junior Data Scientist | 22000.0 |
| 357 | Junior Developer | 23000.0 |
df[['title', 'salary']].sort_values('salary', ascending=False).head()
| title | salary | |
|---|---|---|
| 26 | Director of Data Science and Decision Science | 150000.0 |
| 6 | Director of Data Science | 150000.0 |
| 68 | Director of Data | 150000.0 |
| 394 | Director of Data Engineering | 150000.0 |
| 58 | Data & Decision Science Director | 150000.0 |
df.loc[132, 'salary'] = 100000
Analyse the distribution of named entities
Our dataset above contains a column called skills that includes a list of the unique named entities recognised by our custom named entity recognition system. To analyse these skills individually we can use the Pandas explode() function to split the list up over multiple rows. We’ll split the data into rows and then return just the skill and the salary for each one.
df_skills = df.explode('skills')
df_skills[['skills', 'salary']].sample(5)
| skills | salary | |
|---|---|---|
| 166 | r | 25000.0 |
| 547 | aws | 45000.0 |
| 506 | scala | 75000.0 |
| 563 | azure | 45000.0 |
| 293 | deep learning | 80000.0 |
To understand which roles are most sought after by UK data science employers we can use the Pandas groupby() function with an agg() function. We’ll group the data by the individual skill and then calculate the number of roles in which it appears, then the minimum, maximum, mean, and median salary for each skill.
Roles that mention “data science” range have an average salary of £58,828 and a median of £55,000, compared to those that mention “data engineering”, which carry an average salary of £60,221 and a median of £60,000.
There’s not a huge difference between the salaries of data scientists and data engineers in the UK and demand for data scientists is higher than that for data engineers. Similarly, more than three times as many roles are looking for Python compared to R, with salaries for Python developers being higher on average.
df_summary = df_skills.groupby('skills').agg(
roles=('title', 'count'),
min_salary=('salary', 'min'),
max_salary=('salary', 'max'),
avg_salary=('salary', 'mean'),
median_salary=('salary', 'median'),
).sort_values('roles', ascending=False)
df_summary
| roles | min_salary | max_salary | avg_salary | median_salary | |
|---|---|---|---|---|---|
| skills | |||||
| data science | 348 | 20000.0 | 150000.0 | 58828.077586 | 55000.0 |
| python | 344 | 20000.0 | 150000.0 | 58382.267442 | 55000.0 |
| sql | 270 | 22000.0 | 150000.0 | 56075.425926 | 50000.0 |
| computer vision | 212 | 20000.0 | 150000.0 | 64617.924528 | 60000.0 |
| data engineering | 173 | 25000.0 | 150000.0 | 60221.410405 | 60000.0 |
| aws | 151 | 23000.0 | 150000.0 | 65152.317881 | 65000.0 |
| r | 117 | 20000.0 | 150000.0 | 51152.692308 | 45000.0 |
| azure | 82 | 23000.0 | 125000.0 | 53826.268293 | 50000.0 |
| spark | 81 | 30000.0 | 125000.0 | 68774.740741 | 65000.0 |
| gcp | 54 | 25000.0 | 150000.0 | 63777.777778 | 65000.0 |
| data warehouse | 51 | 28000.0 | 85000.0 | 57254.901961 | 55000.0 |
| data pipelines | 45 | 34000.0 | 110000.0 | 58851.200000 | 60000.0 |
| kafka | 44 | 30000.0 | 125000.0 | 74035.227273 | 75000.0 |
| data analytics | 44 | 22000.0 | 120000.0 | 54500.000000 | 50000.0 |
| machine learning | 42 | 32000.0 | 110000.0 | 62309.523810 | 60000.0 |
| java | 40 | 23000.0 | 110000.0 | 59600.000000 | 57500.0 |
| docker | 38 | 25000.0 | 125000.0 | 67315.789474 | 70000.0 |
| kubernetes | 36 | 25000.0 | 125000.0 | 70416.666667 | 70000.0 |
| data analysis | 36 | 22000.0 | 90000.0 | 45803.222222 | 45000.0 |
| airflow | 36 | 50000.0 | 110000.0 | 68611.111111 | 70000.0 |
| deep learning | 35 | 32000.0 | 110000.0 | 66942.857143 | 65000.0 |
| scala | 33 | 40000.0 | 110000.0 | 65757.575758 | 60000.0 |
| data visualisation | 32 | 25000.0 | 100000.0 | 42984.375000 | 45000.0 |
| nlp | 28 | 32000.0 | 85000.0 | 55428.571429 | 55000.0 |
| hadoop | 26 | 40000.0 | 95000.0 | 64230.769231 | 60000.0 |
| c | 23 | 22000.0 | 150000.0 | 62434.782609 | 60000.0 |
| sas | 20 | 27000.0 | 70000.0 | 45200.000000 | 40000.0 |
| javascript | 17 | 23000.0 | 75000.0 | 51000.000000 | 50000.0 |
| nosql | 17 | 23000.0 | 85000.0 | 55941.176471 | 55000.0 |
| tensorflow | 17 | 40000.0 | 100000.0 | 68235.294118 | 70000.0 |
| mysql | 15 | 25000.0 | 75000.0 | 57000.000000 | 60000.0 |
| postgresql | 15 | 25000.0 | 75000.0 | 59866.666667 | 70000.0 |
| c++ | 13 | 20000.0 | 85000.0 | 52384.615385 | 50000.0 |
| elasticsearch | 12 | 45000.0 | 75000.0 | 69166.666667 | 75000.0 |
| matlab | 10 | 25000.0 | 70000.0 | 43900.000000 | 42500.0 |
| numpy | 10 | 35000.0 | 70000.0 | 56000.000000 | 57500.0 |
| pytorch | 10 | 45000.0 | 90000.0 | 71500.000000 | 70000.0 |
| data mining | 8 | 45000.0 | 80000.0 | 60000.000000 | 60000.0 |
| pandas | 8 | 35000.0 | 70000.0 | 50000.000000 | 47500.0 |
| keras | 6 | 40000.0 | 90000.0 | 64166.666667 | 70000.0 |
| mongodb | 6 | 55000.0 | 100000.0 | 70000.000000 | 65000.0 |
| storm | 6 | 50000.0 | 75000.0 | 56666.666667 | 52500.0 |
| hive | 6 | 45000.0 | 70000.0 | 58333.333333 | 60000.0 |
| css | 5 | 23000.0 | 50000.0 | 35600.000000 | 35000.0 |
| oracle | 5 | 25000.0 | 45000.0 | 37600.000000 | 38000.0 |
| scipy | 3 | 40000.0 | 70000.0 | 58333.333333 | 65000.0 |
| data visualization | 3 | 22000.0 | 40000.0 | 31333.333333 | 32000.0 |
| php | 3 | 28000.0 | 60000.0 | 40666.666667 | 34000.0 |
| plotly | 3 | 35000.0 | 70000.0 | 56666.666667 | 65000.0 |
| neo4j | 3 | 70000.0 | 75000.0 | 73333.333333 | 75000.0 |
| nltk | 2 | 50000.0 | 50000.0 | 50000.000000 | 50000.0 |
| mssql | 2 | 45000.0 | 45000.0 | 45000.000000 | 45000.0 |
| html | 2 | 23000.0 | 50000.0 | 36500.000000 | 36500.0 |
| data wrangling | 1 | 50000.0 | 50000.0 | 50000.000000 | 50000.0 |
| data preparation | 1 | 65000.0 | 65000.0 | 65000.000000 | 65000.0 |
| ruby | 1 | 80000.0 | 80000.0 | 80000.000000 | 80000.0 |
| db2 | 1 | 25000.0 | 25000.0 | 25000.000000 | 25000.0 |
| scikit-learn | 1 | 45000.0 | 45000.0 | 45000.000000 | 45000.0 |
| seaborn | 1 | 65000.0 | 65000.0 | 65000.000000 | 65000.0 |
| cassandra | 1 | 60000.0 | 60000.0 | 60000.000000 | 60000.0 |
| matplotlib | 1 | 45000.0 | 45000.0 | 45000.000000 | 45000.0 |
| flume | 1 | 50000.0 | 50000.0 | 50000.000000 | 50000.0 |
Create box plots for each skill
To understand the distribution in salary for each skill identified by our custom named entity recognition system we can use Seaborn and Matplotlib boxplots for data visualisation. First, we’ll examine the overall distribution in salaries across the whole dataset.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 6))
sns.boxplot(y=df['salary'])
plt.title('Distribution of Salaries')
plt.show()
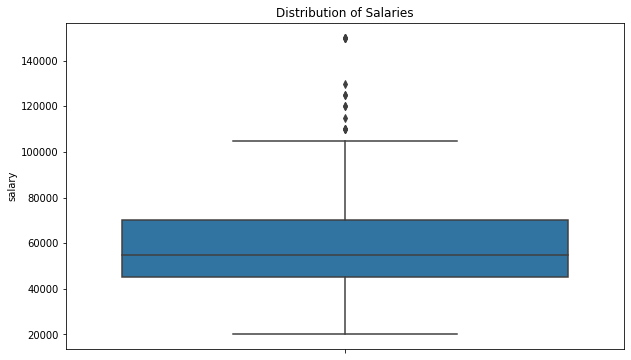
Data science roles in the UK range from a salary of £20,000 at the very, very bottom and rise to £150,000 at the top for director level roles. The overall mean salary is £58,941 and the median is £55,000. This varies according to both the nature of the role (i.e. data science versus data engineering), the skills required in the role, and the level of the role.
df['salary'].min()
20000.0
df['salary'].max()
150000.0
df['salary'].mean()
58941.05995717345
df['salary'].median()
55000.0
Visualising the salary by skill
Next, we’ll use a Seaborn boxplot to visualise the salary ranges for each individual skill. Boxplots, or box and whisker plots, show a coloured box representing the interquartile range, a middle line representing the median value, and whiskers representing the outer limits. Outliers are represented as dots.
plt.figure(figsize=(10, 40))
sns.boxplot(y='skills', x='salary', data=df_skills, orient='h')
plt.title('Distribution of Salaries by Skill')
plt.show()
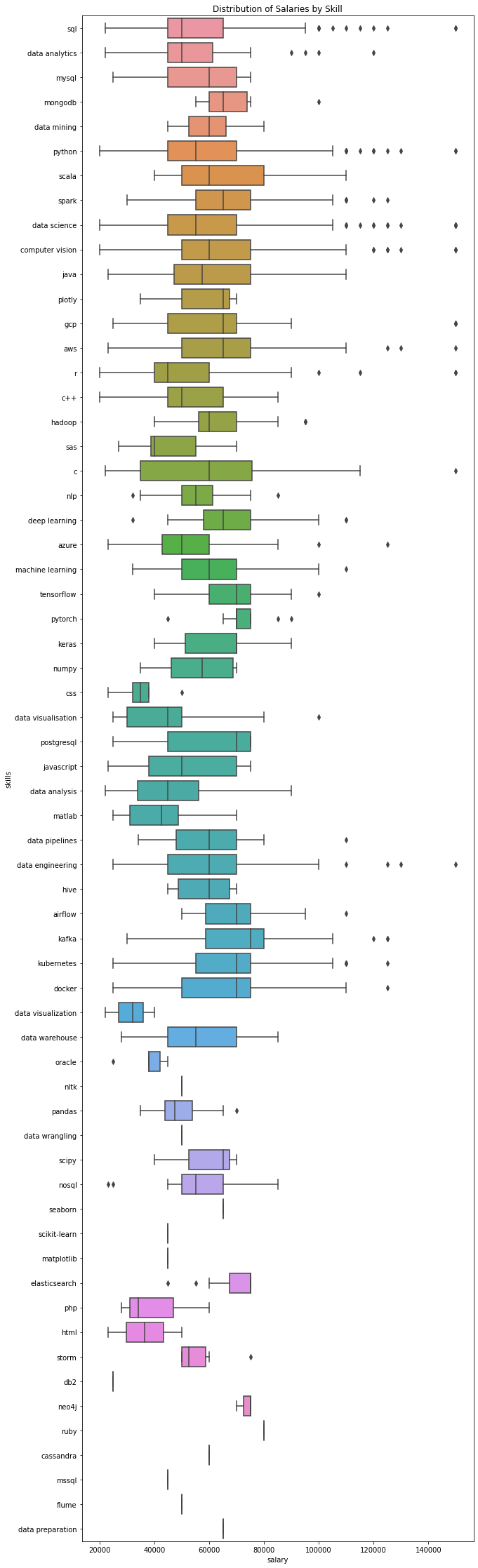
Broad areas
Broadly speaking, the data suggests that median salaries for data engineering roles tend to be a bit higher than those for data science roles, but this changes at the top level, where data science director roles warrant salaries of up to £150K.
broad_skills = ['data science', 'data engineering', 'data visualisation',
'data analytics', 'data warehouse', 'data pipelines', 'data munging',
'data preparation', 'data wrangling', 'data cleaning']
df_subset = df_skills[df_skills['skills'].isin(broad_skills)]
df_summary = df_subset.groupby('skills').agg(
roles=('title', 'count'),
min_salary=('salary', 'min'),
max_salary=('salary', 'max'),
avg_salary=('salary', 'mean'),
median_salary=('salary', 'median'),
).sort_values(['roles', 'median_salary'], ascending=False)
df_summary.head(10)
| roles | min_salary | max_salary | avg_salary | median_salary | |
|---|---|---|---|---|---|
| skills | |||||
| data science | 348 | 20000.0 | 150000.0 | 58828.077586 | 55000.0 |
| data engineering | 173 | 25000.0 | 150000.0 | 60221.410405 | 60000.0 |
| data warehouse | 51 | 28000.0 | 85000.0 | 57254.901961 | 55000.0 |
| data pipelines | 45 | 34000.0 | 110000.0 | 58851.200000 | 60000.0 |
| data analytics | 44 | 22000.0 | 120000.0 | 54500.000000 | 50000.0 |
| data visualisation | 32 | 25000.0 | 100000.0 | 42984.375000 | 45000.0 |
| data preparation | 1 | 65000.0 | 65000.0 | 65000.000000 | 65000.0 |
| data wrangling | 1 | 50000.0 | 50000.0 | 50000.000000 | 50000.0 |
Data engineering skills
Looking in detail at some of the data engineering specific skills, we can see that they tend to have higher average salaries than many of the purely data science skills. Average salaries by skill for most data engineering skills is £53K to £74K.
data_engineering_skills = ['spark', 'scala', 'kafka', 'kubernetes',
'docker', 'aws', 'gcp', 'azure', 'nosql', 'hadoop', 'hive',
'pig', 'flume', 'airflow', 'etl', 'data lake',
'data warehouse', 'data pipelines']
df_subset = df_skills[df_skills['skills'].isin(data_engineering_skills)]
df_summary = df_subset.groupby('skills').agg(
roles=('title', 'count'),
min_salary=('salary', 'min'),
max_salary=('salary', 'max'),
avg_salary=('salary', 'mean'),
median_salary=('salary', 'median'),
).sort_values(['roles', 'median_salary'], ascending=False)
df_summary.head(10)
| roles | min_salary | max_salary | avg_salary | median_salary | |
|---|---|---|---|---|---|
| skills | |||||
| aws | 151 | 23000.0 | 150000.0 | 65152.317881 | 65000.0 |
| azure | 82 | 23000.0 | 125000.0 | 53826.268293 | 50000.0 |
| spark | 81 | 30000.0 | 125000.0 | 68774.740741 | 65000.0 |
| gcp | 54 | 25000.0 | 150000.0 | 63777.777778 | 65000.0 |
| data warehouse | 51 | 28000.0 | 85000.0 | 57254.901961 | 55000.0 |
| data pipelines | 45 | 34000.0 | 110000.0 | 58851.200000 | 60000.0 |
| kafka | 44 | 30000.0 | 125000.0 | 74035.227273 | 75000.0 |
| docker | 38 | 25000.0 | 125000.0 | 67315.789474 | 70000.0 |
| airflow | 36 | 50000.0 | 110000.0 | 68611.111111 | 70000.0 |
| kubernetes | 36 | 25000.0 | 125000.0 | 70416.666667 | 70000.0 |
Data science skills
There are more data science roles available than there are for data engineering roles and the spread of salaries is broader. The average salaries per skill for this subset range from ~£43K for data visualisation up to £71K for Pytorch roles - other deep learning specific roles tend to carry higher salaries too.
data_science_skills = ['python', 'r', 'machine learning', 'deep learning',
'neural networks', 'tensorflow', 'pytorch', 'scikit-learn',
'pandas', 'numpy', 'scipy', 'matplotlib', 'seaborn', 'plotly',
'bokeh', 'd3', 'jupyter', 'jupyterlab', 'rstudio', 'tableau',
'power bi', 'data visualisation', 'data analytics', 'data munging',
'data preparation', 'data wrangling', 'data cleaning']
df_subset = df_skills[df_skills['skills'].isin(data_science_skills)]
df_summary = df_subset.groupby('skills').agg(
roles=('title', 'count'),
min_salary=('salary', 'min'),
max_salary=('salary', 'max'),
avg_salary=('salary', 'mean'),
median_salary=('salary', 'median'),
).sort_values(['roles', 'median_salary'], ascending=False)
df_summary.head(10)
| roles | min_salary | max_salary | avg_salary | median_salary | |
|---|---|---|---|---|---|
| skills | |||||
| python | 344 | 20000.0 | 150000.0 | 58382.267442 | 55000.0 |
| r | 117 | 20000.0 | 150000.0 | 51152.692308 | 45000.0 |
| data analytics | 44 | 22000.0 | 120000.0 | 54500.000000 | 50000.0 |
| machine learning | 42 | 32000.0 | 110000.0 | 62309.523810 | 60000.0 |
| deep learning | 35 | 32000.0 | 110000.0 | 66942.857143 | 65000.0 |
| data visualisation | 32 | 25000.0 | 100000.0 | 42984.375000 | 45000.0 |
| tensorflow | 17 | 40000.0 | 100000.0 | 68235.294118 | 70000.0 |
| pytorch | 10 | 45000.0 | 90000.0 | 71500.000000 | 70000.0 |
| numpy | 10 | 35000.0 | 70000.0 | 56000.000000 | 57500.0 |
| pandas | 8 | 35000.0 | 70000.0 | 50000.000000 | 47500.0 |
Matt Clarke, Friday, December 02, 2022













Other posts you might like

How to use the Pandas truncate() function
Have you ever needed to chop the top or bottom off a Pandas dataframe, or extract a specific section from the middle? If so, there’s a Pandas function called truncate()...

How to use Spacy for noun phrase extraction
Noun phrase extraction is a Natural Language Processing technique that can be used to identify and extract noun phrases from text. Noun phrases are phrases that function grammatically as nouns...
